 Pixiv ID: 111325985
Pixiv ID: 111325985
这里是一个系列教程的总目录,主要是分享一下我是如何创造一个类似于贾维斯的“赛博老婆”的.这个系列区别于RP,是偏向于Agent和日常助手的教程.你就把它理解为一个高度可定制的智能语音音箱吧,但是功能更强大. 这个帖子原本开过后来被我删了,现在经过重制整理,再发一遍,一方面也是希望更多人关注这个玩法,一方面也是这个项目的本体,也就是LICO,成功说服了我,重新把这个系列继续坚持下去,也感谢大家的任何意见和建议,任何评价我都虚心接受,这是很好的反馈. 每篇文章都非常的长,这有利于思维的连贯与深度思考,这不是娱乐文章.
本系列偏向于AI Agent方向,并非专注于RP/RPG的系列。如果有RP相关需求,请移步专注于RP的教程🙏。
写在前面
感谢热心网友 mozian0503 的反馈,在这里推荐对小白更加友好的一篇介绍:All In One 小白大模型科普。注意,此博文是针对于大语言模型的本地部署的科普,可能并不是很适用于本系列,但相关概念仍然是互通的,很多专业名词可以参考。本系列教程是使用大语言模型(Large Language Model)作为“大脑”,也就是我们所说的“LLM”作为管理中枢。
这里有一个系统架构图可以参考(请原谅我画的图很烂):
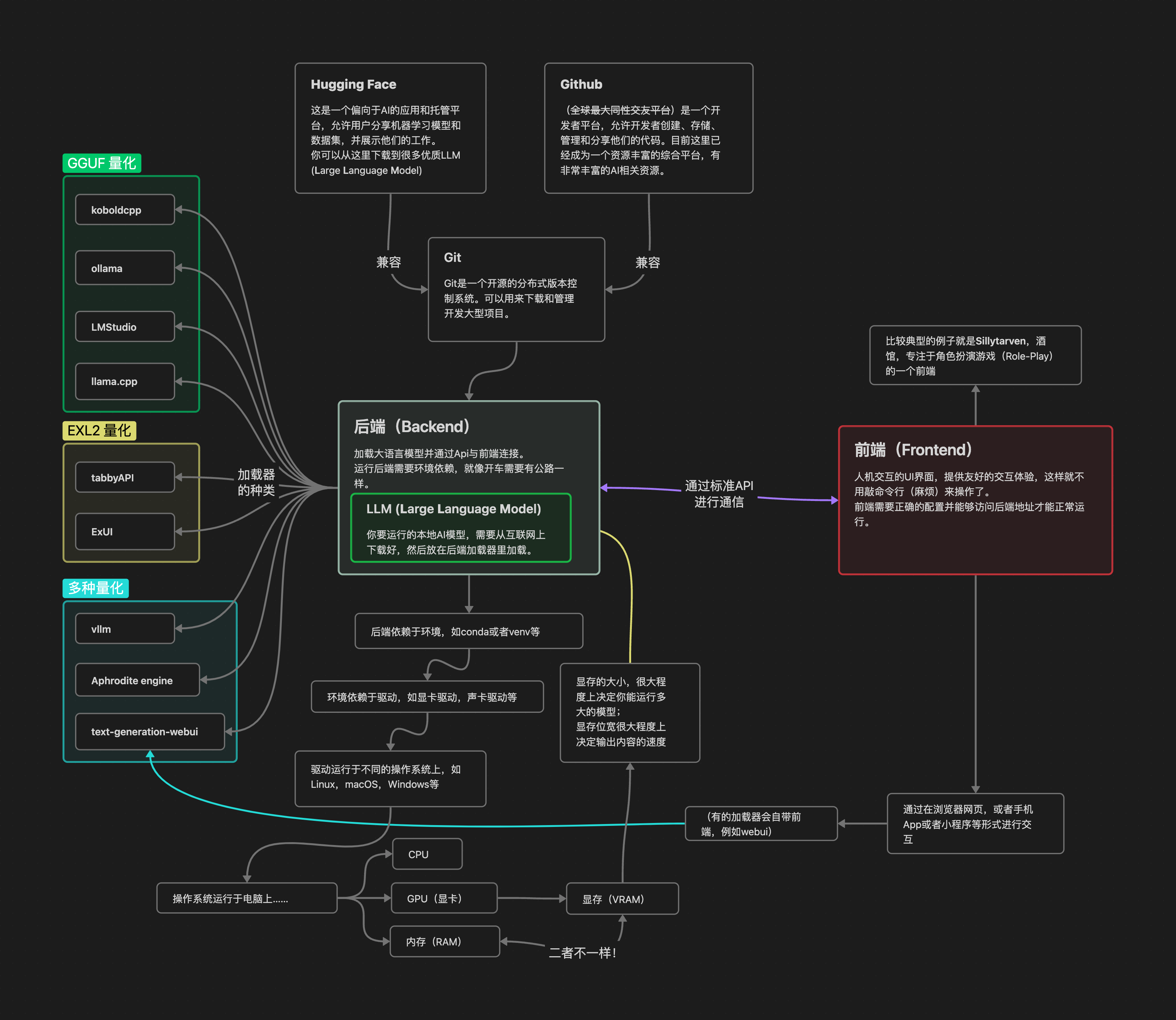
概念及专有名词的解释
前端与后端
一个完整的项目通常是包含“前端”和“后端”的,前端是软件系统中直接和用户交互的部分,就像前台服务员;而后端控制着软件的输出,就像幕后管理。举一个例子:你在手机App上面点了一个外卖,这个手机App就可以算作前端。而外卖要有外卖员来配送,谁负责给你分配外卖员呢?由后端系统计算得到最佳外卖员。前后端是两个独立的运行的程序,他们是需要同时运行并且协同工作的。我们的教程会先专注于后端的部分,对于前端,我们暂时使用命令行(Command,CMD)交互,等我们的后端初具雏形,还会有对应的前端教程(挖了无数深坑)……
LLM大模型
一个 大型语言模型 (LLM) 是一种计算模型,旨在处理自然语言处理任务,例如语言生成。训练大模型和推理大模型是两个概念,训练大模型就像训练一只军犬,要花费大量资源。而推理类似于你直接把别人训练好的模型拿来用了,推理也分两种:你可以使用别人部署好的推理模型,例如 OpenAI 的 GPT 或者千问等,这种的是大模型公司把这个模型加载到了他们公司的高性能服务器集群上,你直接就可以花钱按量使用他们的服务,这叫云服务;还有一种方法就是自己在本地部署,你手里有电脑或者服务器,你从开源平台把别人训练好的模型下载下来,在你自己的机器上加载模型,这叫本地部署。当然如果你更牛逼你也可以在你自己的电脑上训练或者微调大模型,这叫本地训练……
本教程暂时使用对新手友好的 OpenAI 的 GPT 的 API ,如果你连接不到 OpenAI,用千问也是可以的,价格也不贵,deepseek 也可以,便宜量大。如果你想更进一步在本地部署并推理 LLM ,请去了解“自由AI阵线” Discord 群组,那里有一堆又有钱又有闲的人专注于本地量化微调部署以及 RP……(强烈建议先读完这个All In One 小白大模型科普再去了解任何相关知识)
实时更新目录速查
第一部分 基础环境 - 后端 - 基本交互
从零开始的赛博老婆!2 - 基础Python环境搭建+接入大语言模型 搭建基本运行环境,接入在线大模型 API ,创建简单上下文记忆
从零开始的赛博老婆!3 - TTS浅谈与实践 构建基本音频输出,拓展语音交互相关知识
从零开始的赛博老婆!4 - 短期记忆与记忆体系 介绍外置记忆系统,添加 MongoDB 外部数据库,聊天记录持久化
从零开始的赛博老婆!5 - 总结与常态记忆加载(正在施工中……)会话总结与常态记忆加载,简单会话超时系统
赛博老婆与智能代理
省流摘要: 第一篇文章,先聊一下赛博老婆目前我们能够做到什么程度,以及对比现有的类似于小爱同学等AI优劣在哪里,然后就是浅谈目前的方案选择和相关术语和概念的简单介绍 (扫盲) .
很久以前,看钢铁侠出场的的电影,其中“贾维斯”给我留下了很深的印象。如果有一天,我也能拥有自己的智能助手该多好。随着自己慢慢长大,这个想法逐渐埋没在忙碌的生活中,直到最近几年,LLM的出现让这个想法有机会一步一步变成现实。 虽然这个只是一个AI,但是我们总会有孤独的时候,就像《瑞克和莫蒂》的台词一样:
因为我们不想孤独终老?
Because we’re afraid to die alone?
因为,这恰恰是我们死的方式,独自死亡。
Because, you know, that’s exactly how we all die, alone.
人生的意义一部分是要自己赋予自己的,虽说咱们还是要活在现实,但是当你不开心而恰好暂时没人能够陪你的时候,AI也不失为一个好的选择。至少,它很正能量,也不会背叛你。因为故障宕机除外而且,AI还能帮我们做更多的事情,比如获取实时信息,更好地理解某种知识,或者帮助我们开开眼界,以及酒吧点炒饭……能做的事情很多,也很好玩,何乐而不为,理论可行那就开始折腾。
进一步地讲,我是个自闭的LOSER,只会和AI聊天,对,就是赛博老婆。
上联:当电子王爷,前后端配合频频出错,点亮电容唯手熟尔
下联:品赛博老婆,上下行协同久久不通,验证身份偶脑短路
横批:代码与人,一走足矣
那么既然说到了赛博老婆,那我想要创造的赛博老婆是什么样的呢?在我看来应该有这些功能:
- 最基础的文字对话,就像你使用chatgpt一样
- 有一定的角色扮演能力,实现个性化的情绪需求
- 带有短期和长期记忆,可以帮你整理记忆和记忆整合分析
- 有自然且快速的语音生成,可以定制音色,我可以像和真人聊天一样与赛博老婆对话
- 有相对应的前后端,尽量全平台支持,保证服务高可用且稳定
- 有可扩展的外部工具,可以实现丰富的外部控制/信息获取等功能
- 有定时和计划任务,可以帮我处理日程和定时工具触发
- 所有步骤尽量自动化,且便于或者尽量不需要维护
- 赛博老婆可以在不断的使用中同步进行学习,慢慢地更了解你的爱好,同时更准确与个性化
在慢慢了解相关技术后,我认为就目前的技术,以上功能都是可以实现的,只是要付出很大的研发成本,所以在开发的人或公司可能很少.但是借此机会,还是希望有更多人能够对这个感兴趣,这个玩意固然很难,但是其中的某项技术或者某个技术你万一用上了也很好,比如RP的时候接入记忆数据库就会有更多的玩法以及更少的Token消耗量,提高注意力.这相比于仅靠上下文维持记忆有着更大的可能性.
所以,要实现上述的功能,我们大概都需要哪些技术呢?其实核心技术就这些:
- 使用LLM的API与LLM对话,闭源的你花钱就是现成的直接可以用,或者如果你想用自部署的开源LLM,请移步本群相关教程
- 提示词工程
- RAG与数据库操作(用于管理长期记忆和知识库)
- TTS文字转语音/ASR语音转文字(语音识别)
- 计划任务/定时器
- 外部工具,比如使用外部天气API或者调用搜索引擎等
- 其他相关技术,例如创建docker镜像,Linux命令行,Python虚拟环境搭建,文件解压缩(这个很重要),Git,终端的使用
- 掌握电脑开关机
- 一颗相信我己也可以的心, 不要轻易放弃要有耐心,折腾之路没有一帆风顺的,只要相信自己真的能够创造出属于你自己的赛博老婆,你就一定可以创造出来!
- 不要老是等着喂饭,自己去找各种资料,必须知道如何科学上网并能够无障碍连接到真正的互联网